Arjun Yadav
Distillation of The Offense-Defense Balance of Scientific Knowledge
Aug 12, 2022
Link to the paper (also serves as credit for the image above).
Note: This post is a replacement post for July 2022 and was last edited on Aug 26, 2022.
Introduction
This paper discusses the balance between AI research contributing to misuse and protections against such misuse. AI research is permeated with discussions over disclosure norms and researchers are concerned about the potential misuse their research could hold. By taking the example of vulnerability disclosure in computer security, this paper aims to draw helpful analogies between the two fields.
Computer Security Analogy
A common justification for the belief that the benefits of research outweigh any negative impact in the computer security scene is the defense view: malicious actors will figure out attacks regardless, and research helps us to defend from such attacks.
This view has been seen in AI research. Richard Socher, the former chief scientist at Salesforce, criticized OpenAI for their "responsible disclosure" of GPT-2:
Similar to information security research, it is necessary for these tools to be accessible, so that researchers have the resources that expose and guard against potentially malicious use cases.
To prove the point that replication is straightforward with pre-requisite knowledge, two master's students at Brown University replicated and published their version of GPT-2.
The Offense-Defense Balance
The formal definition of The Offense-Defense Balance is:
[the] relative ease of carrying out and defending against attacks.
And it is based on the following parameters:
- Counterfactual possession - how easy/difficult is it for people to re-discover the research independently?
- Implementation capacity - how easy/difficult is it to apply the research? Is it possible for offense knowledge to transfer to defensive knowledge, and vice versa? What about the cost involved?
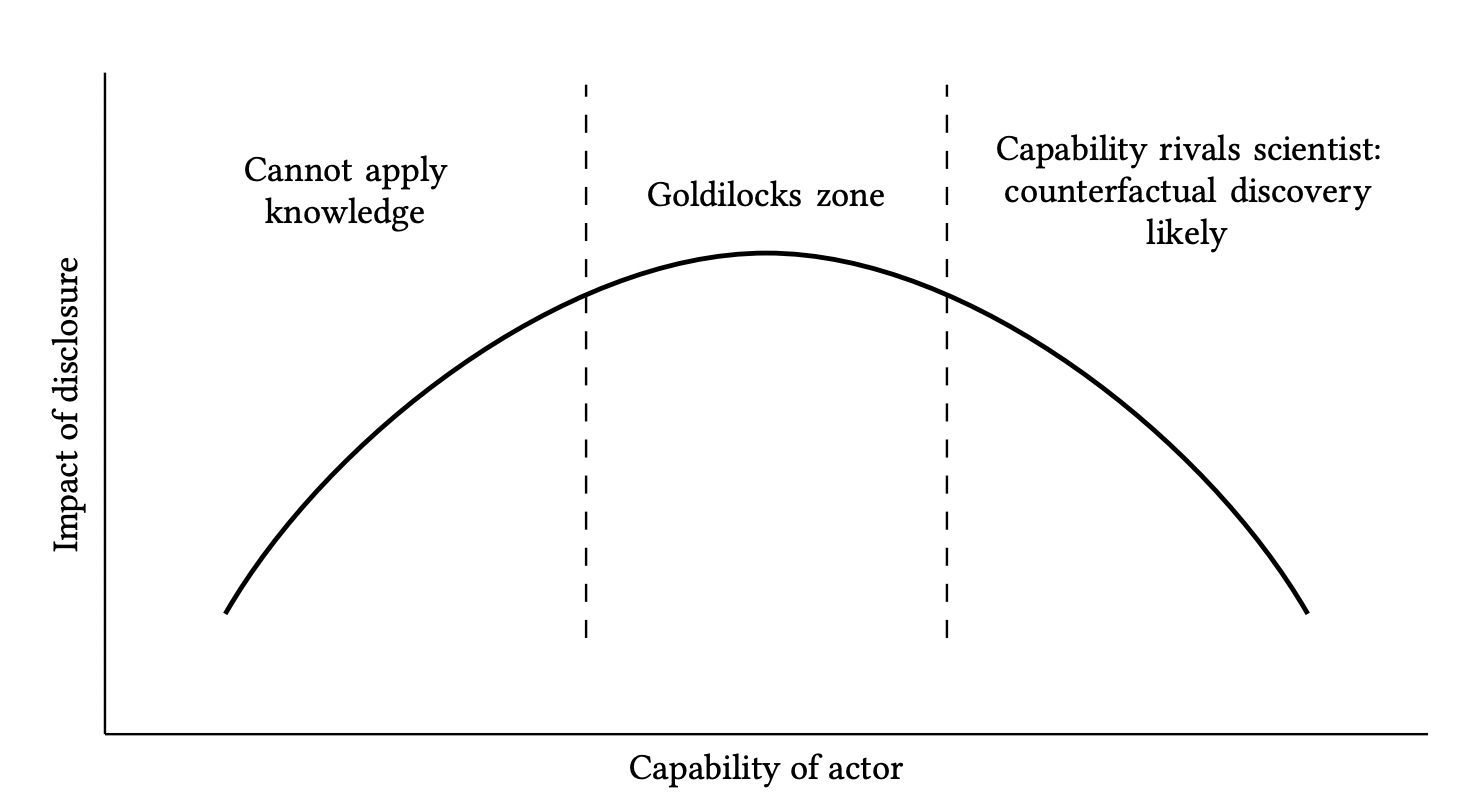
Based on these two parameters, we can sketch a graph to highlight a "Goldilocks zone", where we have enough information to apply the knowledge but not enough to independently discover it:
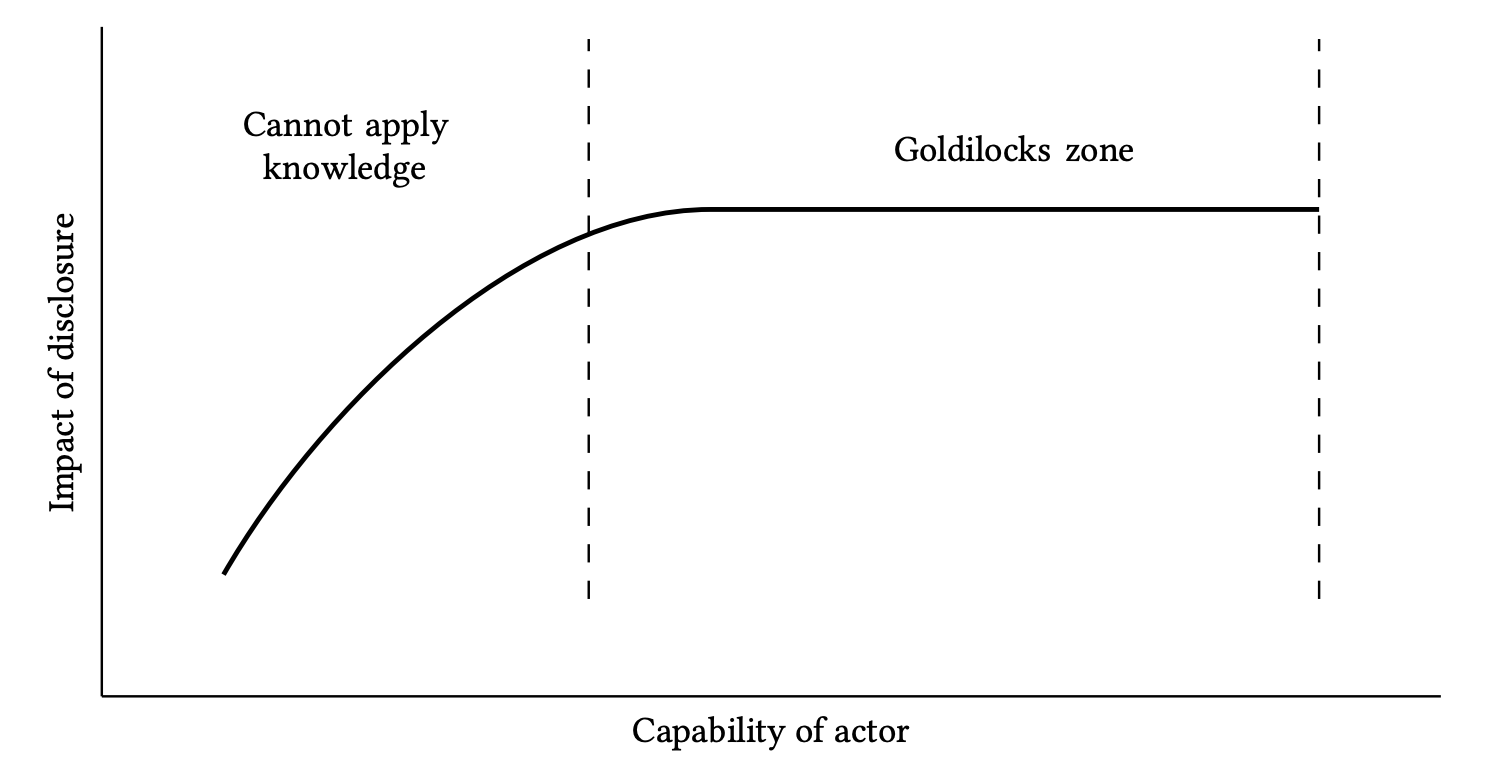
We note that, if the knowledge needed to implement the research is quite high, the Goldilocks zone is skewed to the left:
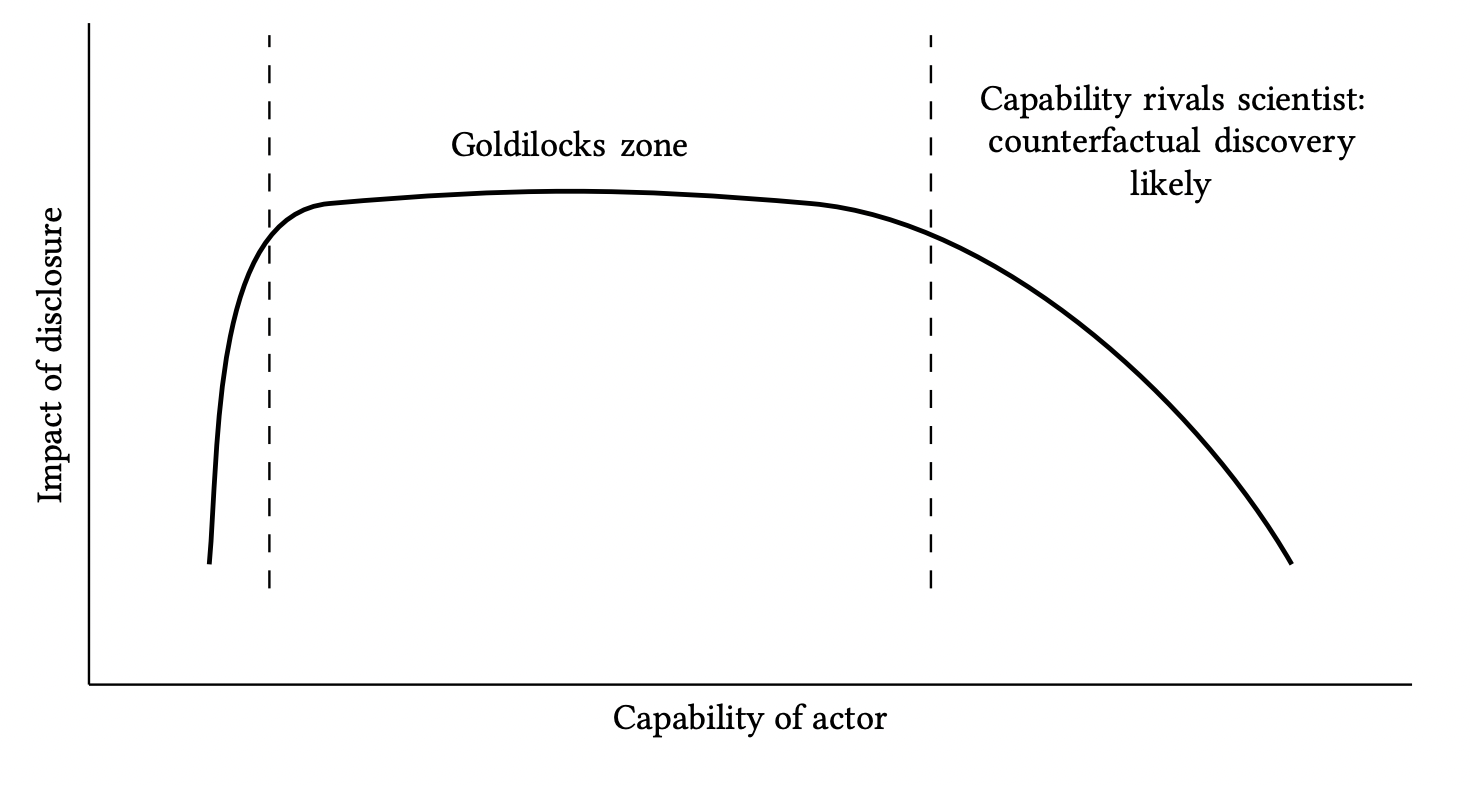
If limited knowledge is required to implement or exploit the research, the Goldilocks zone skews to the right:
Preliminary results from applying this framework to AI research
Social Disruption
AI misuse (for now) is mainly linked to social disruption (take deepfakes being used to trick companies and, at a wide scale, it is costly to fix. And often, intervention is needed with pre-existing research for defense. This means that, in this limited scenario, AI publications could have more limited defensive benefits as time goes on.
Computer security mainly deals with digital issues that, while can cause wide-scale disruption (Y2K, the Morris Worm), are generally more "receptible" to repairs. The Morris worm (which rendered 6000 machines inoperable) was halted the day after it was detected thanks to software patching.
To summarize:
The tractability of solutions will vary from case to case, and in many cases, some solution (technical, institutional, or behavioural) will be able to counter AI misuses. The key suggestion is that the (AI) vulnerabilities will be on average harder to patch than software vulnerabilities, and so AI researchers cannot assume that their publication will always have a defensive bias.
Detection
Say we had an AI system that could detect AI misuse. What would happen to the defensive benefit of AI research then?
If research is published on AI misuse detection, AI systems could simply be trained against such detection systems. Thus, the value of such research will depend on the limits of the detection systems.
Further, it may not be feasible to deploy such AI systems that can detect misuse due to cost or privacy concerns.
Counterfactual possession of AI Knowledge
The last factor we'll look at that could affect this framework is the counterfactual possession of AI knowledge.
If we take the example of text generation: how much benefit do bad actors gain from AI research? It depends on the content of the research and the access to AI knowledge and computing power. This is why state actors may not benefit so much from AI research.
Conclusion
The impact of disclosing research should be considered with a plethora of other factors: such as norm-setting and maintaining/maximizing benefits from such disclosure.
This topic will vary a lot from field to field in AI research, but this paper hopes that it will aid in thinking critically about the implications of publishing work that could be misused.