Arjun Yadav
This page serves as my machine learning/AI safety notebook, I hope for this page to serve as a more unstructured knowledge hub of all that I have discovered in ML/AIS in the future.
Notebook
AI Safety Fundamentals - Governance
-
Session 5: AI Policy Levers: Should have prepared better for this session. Oh well.
-
Session 4: Obstacles to Controlling AI: Great session (finally!) and thoroughly enjoyed the debate!
-
Session 3: The Perils of AI: Didn't enjoy this session as much, but again - still valuable.
-
Session 2: The Promise of AI: A bit more slow, but still really valuable.
-
Session 1: Introduction to Artificial Intelligence: Figure 01 and Palantir were wild, also, we made a song!
AI Safety Fundamentals - Alignment
-
Session 8-11: Contined work on my alignment project, which will have its own section in this notebook real soon!
-
Session 7: Contributing to AI Alignment: Gained a lot of clarity in career and a great coincidence happened today!
-
Session 6: Technical governance approaches: Some lovely one-on-ones!
-
Session 5: Mechanistic Interpretability: Dictionary Learning is incredible.
-
Session 4: Scalable Oversight: This session made me feel that I actually know what I'm talking about, a rare feeling.
-
Session 3: Reinforcement learning from human (or AI) feedback: Lovely.
-
Session 2: What is AI Safety?: The gaps are definitely getting filled. (x2)
-
Session 1: AI and the Years Ahead: The gaps are definitely getting filled.
Steering and Evaluation Research + Large Language Models (LLMs)
Articles, Lectures and Thoughts
-
Steering GPT-2-XL by adding an activation vector - LessWrong
-
Intro to Large Language Models - Andrej Karpathy
The full scoop: how do LLMs work?
A large language model consists of two things: a massive file of parameters (llama-2-70b's is almost 140 GB) and a simple C file used to run the architecture that permits the user to input text and get an output back.
The C file isn't interesting, the interesting part is the parameters: which you can think of as a compressed form of the internet, an expensive (think in the millions of dollars) and hard process.
The architecture used to get the parameters is called a transformer, and the first thing we do with transformers is called pre-training, where, from the ~10TB of text, we obtain our base model.
The above process is only done maybe once a year as it's really expensive. But the next step is making the assistant to our large language model which is the interesting part: the part where we can give a prompt and get a response. The process of obtaining this helper model is called fine-tuning and typically requires much less resources.
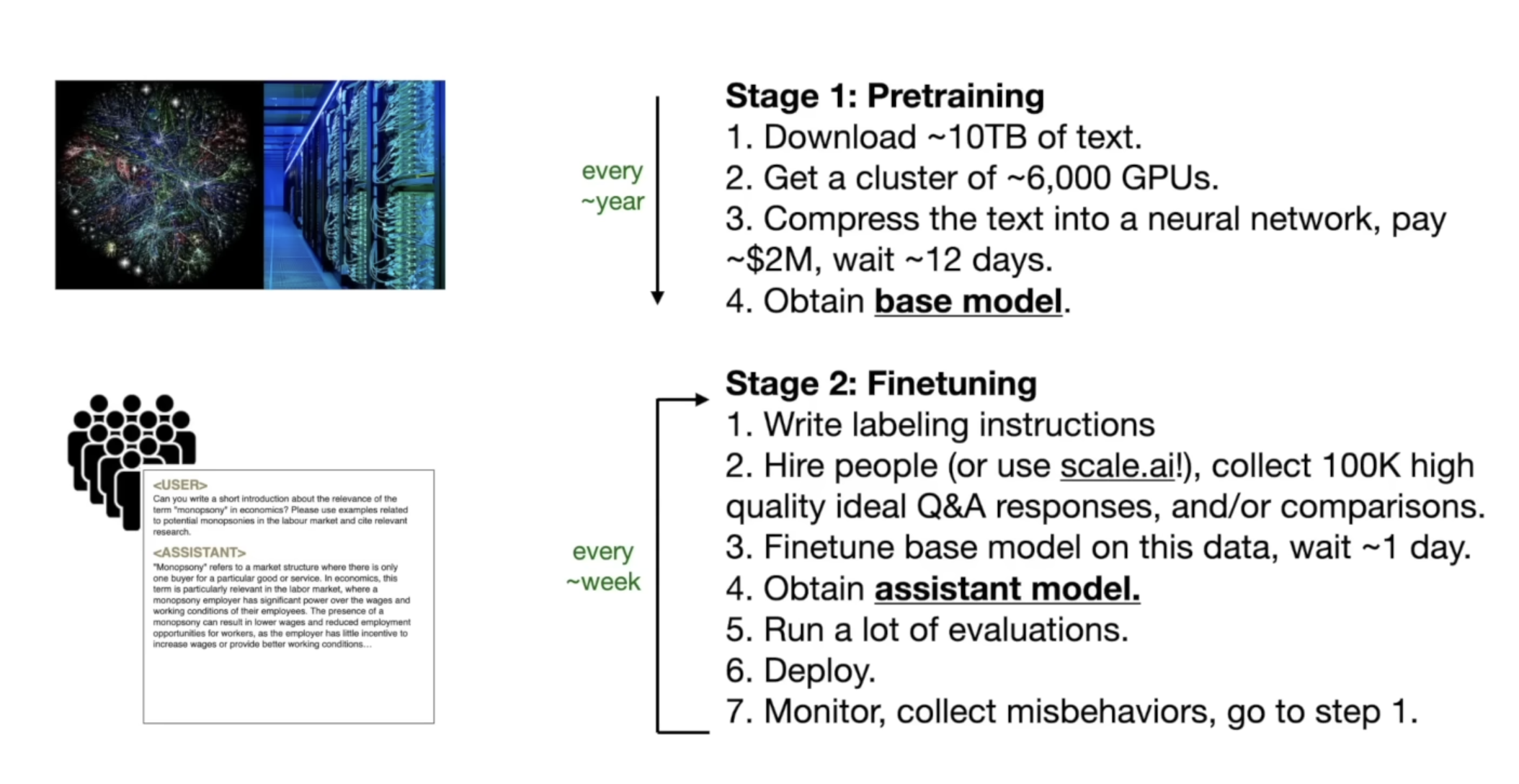
Currently, closed source models (ones where we can only interact through a web interface or an API at best - no access to the weights) outperform open sources one by a fair amount. The rest of the video dives into scaling laws and an excellent summary of some of the core fundamentals of AI safety, highly recommend watching the last 15 minutes in its entirety!
What is Steering?
Put simply, steering is the idea that we can change the course of what a model generates by somehow manipulating its activation vectors, whether that involves changing individual neurons or adding activation vectors.
Achievements
Apr-May 2024
- Applied for ESPR & PAIR 2024!
- Applied for SPAR 2024!
- Applied for the AI Safety Careers Course!
- Part of the Horizon Omega team!
- Applied for the AI Safety, Ethics and Society course!
- Got accepted to AI Safety Fundamentals: Governance course!
Jan-Mar 2024
- Finished with my work for Dioptra!
- Got accepted to AI Safety Fundamentals!
- Got accepted to AI Safety Camp 2024: VAISU project!
Dec 2023
- Became a part of the ai-plans dev team!
- Became a part of the Dioptra research team!
Nov 2023
- Applied to the Inspirit AI Program for Summer 2024 (July 15 - July 26, 5-7:30 PT)!
- Applied to OpenAI's Red Teaming Network!
- Applied to GovAI's blog editor post!
- Applied to AI Safety Fundamentals!
- Applied to AI Safety Camp 2024!
Summer 2023
- Taught high school seniors about machine learning and AI safety!
- Worked with my brother on variational auto-encoders and mechanistic interpretability while he was setting up BAISC.
- Research Assistant Tenureship - got to learn a lot about transformers!
Papers, Notes and Reports
Governance and Policy
Misalignment and Potential Solutions
- Weak-to-Strong Generalization: Eliciting Strong Capabilities with Weak Supervision
- Supervising strong learners by amplifying weak experts
- AI Safety via Debate
- Constitutional AI: Harmlessness from AI Feedback
- CycleGAN: a Master of Steganography
Evaluation Research
We note that in practice, the contemporary AI community still gravitates towards benchmarking intelligence by comparing the skill exhibited by AIs and humans at specific tasks, such as board games and video games. We argue that solely measuring skill at any given task falls short of measuring intelligence, because skill is heavily modulated by prior knowledge and experience: unlimited priors or unlimited training data allow experimenters to “buy” arbitrary levels of skills for a system, in a way that masks the system’s own generalization power. We then articulate a new formal definition of intelligence based on Algorithmic Information Theory, describing intelligence as skill-acquisition efficiency and highlighting the concepts of scope, generalization difficulty, priors, and experience, as critical pieces to be accounted for in characterizing intelligent systems.
Mechanistic Interpretability
-
The Problem: Unsupervised discovery of interpretable features and controllable generation with high-dimensional data are currently major challenges in machine learning.
Proposal: A model based on variational auto-encoders (VAEs) in which interpretation is induced through latent space sparsity with a mixture of Spike and Slab distributions as prior.
Practical Applications of Transformers
-
Exploring Semi-Supervised Learning for Camera Trap Images from the Wild
-
Evaluating the FixMatch Semi-Supervised Algorithm for Unbalanced Image Data
-
Towards an IoT-based Deep Learning Architecture for Camera Trap Image Classification
Multi-headed Attention and Transformers
-
Background: While the Transformer architecture has become the de-facto standard for natural language processing tasks, its applications to computer vision remain limited. In vision, attention is either applied in conjunction with convolutional networks, or used to replace certain components of convolutional networks while keeping their overall structure in place.
Purpose: How can we use a transformer more solely to achieve great results in CV?
Enter, ViT - obtaining results similar to CNNs by slightly tweaking the original transformer model presented in "Attention Is All You Need" and pre-training on large datasets and later fine-tuning to suit smaller, downstream tasks.
An important aspect of this paper was inspecting how the attention can be visualized and how the positional embeddings appear once visualized.
-
EfficientFormer: Vision Transformers at MobileNet:
Purpose: Can transformers (specifically Vision Transformers - ViT) run as fast as MobileNet while obtaining high performance?
Introduction: Dosovitskiy et al. adapt the attention mechanism to 2D images and propose Vision Transformer (ViT): the input image is divided into non-overlapping patches, and the inter-patch representations are learned through MHSA (multi-head self-attention) without inductive bias. However, many bottlenecks exist when using transformers for computer vision applications - and this is the focus of the paper: using latency analysis to see what's bottlenecking their performance and hence, deliver a model that addresses these issues.
Observation 1: Patch embedding with large kernel and stride is a speed bottleneck on mobile devices.
Observation 2: Consistent feature dimension is important for the choice of token mixer. MHSA is not necessarily a speed bottleneck.
Observation 3: CONV-BN is more latency-favorable than LN (GN)-Linear and the accuracy drawback is generally acceptable.
Observation 4: The latency of nonlinearity is hardware and compiler dependent.
The rest of the paper is the implementation (and hairy) mathematics behind the EfficientFormer in PyTorch 1.11 using the Timm library that addresses each of the bottlenecks. This is done mainly through latency driven slimming for their supernet by using a MetaPath and a different Softmax (Gumbel Softmax) implementatoin for their searching when it comes to get the importance score ofr th blocks within each MP for (I believe) the self-attention aspect of the model.
-
Terms and Concepts
(in a rough decreasing order of "high-levelness", these terms tend to get updated as I learn more!)
-
Dictionary Learning - Anthropic's tool for this is great, see this guide as well.
-
Features, Circuit and Universality - This distillation is basically canon at this point.
-
Deceit and Honesty - See this post on LessWrong - really interesting!
-
Reinforcement learning from human feedback - See this post by OpenAI.
-
Mistral's 8x7B and Uncensored Models: Now this, this is interesting. The uncensored models aspect is however, very scary.
-
The Reversal Curse: Ask ChatGPT who is Tom Cruise's mother: you'll get Mary Lee Pfeiffer. Ask ChatGPT who is Mary Lee Pfeiffer's §, it'll say it doesn't know.
-
Gemini by Google: See this post (linkpost of the announcement post, see it for the comments).
-
Monosemanticity: The fact that some neurons only do one thing, making them easier to interpret. Check this out!
-
Pareto frontier: In mathematics, it's just a set of solutions that represents the best trade-off between all the objective functions. Need to learn more about this 'Pareto' guy.
-
Multimodal interface - "Multimodal interaction provides the user with multiple modes of interacting with a system. A multimodal interface provides several distinct tools for input and output of data."
-
Risk Awareness Moment: Risk Awareness Moments are more retroactive in nature: they are moments in our history where major national and/or international bodies come together to get their head straight on a non-partisan issue (e.g.: the ozone layer hole of Antarctica) (this article does a great job explaining RAMs for AI).
-
Mechanistic Interpretability: Essentially, it's a series of techniques that one can employ to try to reverse engineer a neural network: the inner workings of a neural network are something that, on paper, may seem decipherable: but are typically obfuscated by a lot of factors (the main one being dimensionality) (Anthropic)
-
AI Plans and Strategies: A collection of compilations of AI plans and strategies for alignment: 1, 2
-
Generative Adversarial Network: A GAN consists of both an encoder and decoder that essentially battle it out for the encoder to generate more convincing fake images. See an example here.
-
Sparse Coding: A technique to set an encoding function in such a way that it can exploit a high-dimensional space to model a large number of possible features, while being encouraged to use a small subset of non-zero elements to describe each individual observation.
-
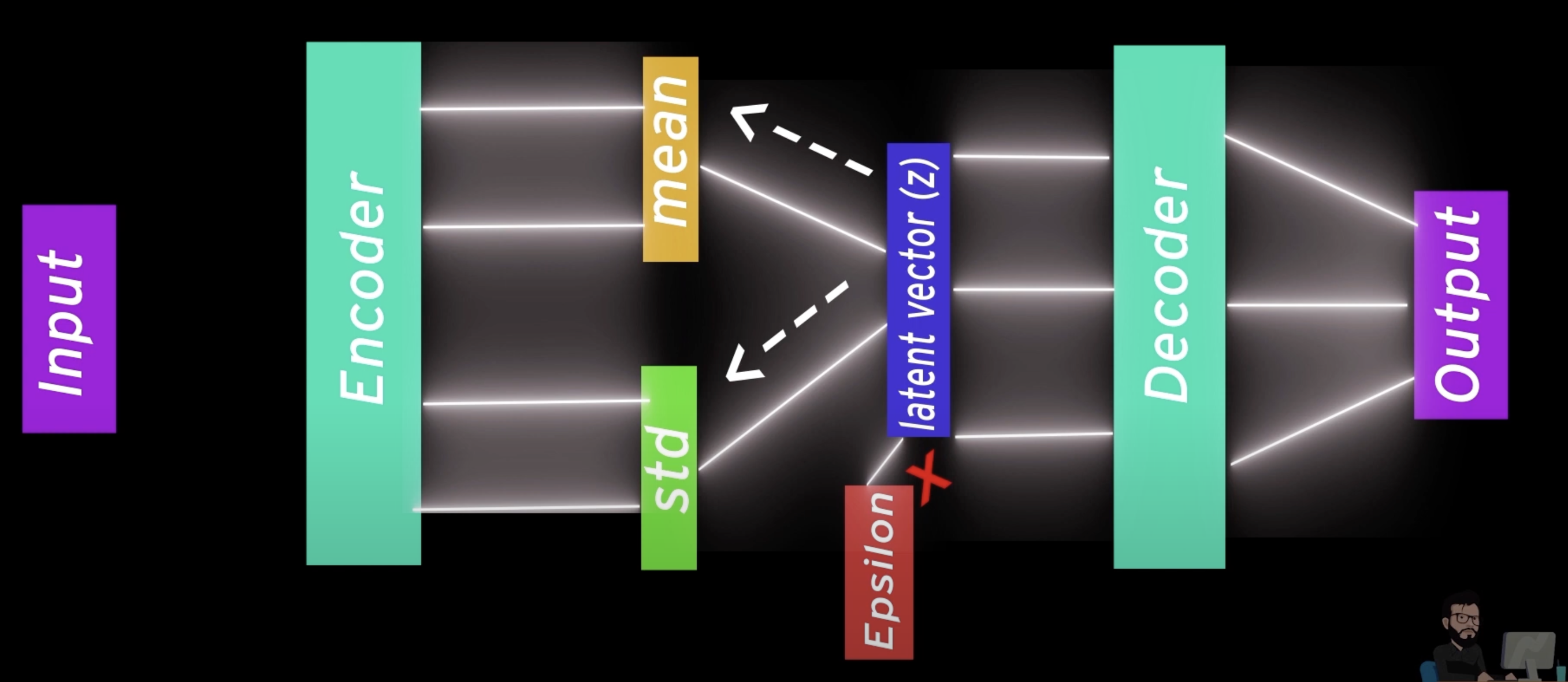
Variational auto-encoder (VAE): A VAE is an autoencoder whose encodings distribution is regularised during the training in order to ensure that its latent space has "good" properties allowing us to generate some new data (in a sense, visualize it in a better manner).
It does this via having a layer that splits the encoder's result into mean and standard deviation, and a latent vector with a separate episilon value for backpropagation to happen properly.
If you wish to see a VAE in action, check out this repository.
-
Auto-encoder: An autoencoder is a type of convolutional neural network (CNN) that converts a high-dimensional input into a low-dimensional one (i.e. a latent vector), and later reconstructs the original input with the highest quality possible. It consists of both an encoder and decoder. An example of its use is removing noise from a dataset (Paperspace Blog).
People I've Met in AI Safety
Note that these are outside of formal projects. I'd also like to shout out two people who are working on (or at least thought of) two really interesting mashups of generative AI with their respective arts (dance and singing).
Meeting with a co-worker at Dioptra
- Interesting chat with someone who is very similar to me: learnt a lot, but a lot more self-reflecting to be done.
Meeting with a former EA VP fellow
- Great to connect with him after a long time! Glad we're both doing well and gave some really great advice on meeting my goals for independent AI safety learning. I also really like the practice he has before every meeting with his pre-email: "Imagine we're done with the call, and it went fantastic. What happened? What did we attend to and resolve?"
Meeting with an eval researcher
- Incredibly useful and provided a lot of clarity, couldn't have asked for a better meeting from the Slack message I had posted in an AI safety workspace.
Meeting with a (former) Berkeley Ph.D. student
- "Honesty is everything" is what I remember most vividly, I wonder if they still hold that opinion...
Related Projects and Posts
Posts
- The Busy Person's Introduction to AI Safety
- Linear algebra in ~10 minutes
- Distillation of The Offense-Defense Balance of Scientific Knowledge